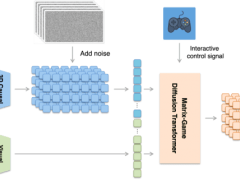
苹果机器学习团队近期在GitHub上掀起波澜,他们发布并开源了一款名为FastVLM的视觉语言模型,为用户提供0.5B、1.5B和7B三种不同规模的版本选择。
这款模型是苹果基于其自研的MLX框架精心打造,同时借助LLaVA代码库进行高效训练。尤为FastVLM针对Apple Silicon设备的端侧AI运算进行了深度优化,旨在为用户提供更为流畅的体验。
技术文档详细揭示了FastVLM的卓越性能。它在保持高精度的同时,实现了高分辨率图像处理的近实时响应,而且所需的计算量远低于同类模型。这一突破性的进展,无疑为视觉语言模型的应用开辟了更广阔的空间。
FastVLM的核心竞争力在于其创新的FastViTHD混合视觉编码器。苹果团队自豪地表示,这款编码器专为高分辨率图像设计,旨在实现高效的VLM性能。与同类模型相比,FastViTHD的处理速度提升了3.2倍,而体积却仅为原来的3.6分之一。这一显著的优势,使得FastVLM在视觉语言模型领域独树一帜。
在具体性能对比中,FastVLM的最小模型版本展现出了惊人的表现。与LLaVA-OneVision-0.5B模型相比,FastVLM的首词元响应速度提升了85倍,而视觉编码器的体积则缩小了3.4倍。当搭配Qwen2-7B大语言模型版本时,FastVLM使用单一的图像编码器便超越了Cambrian-1-8B等近期研究成果,首词元响应速度更是提升了7.9倍。
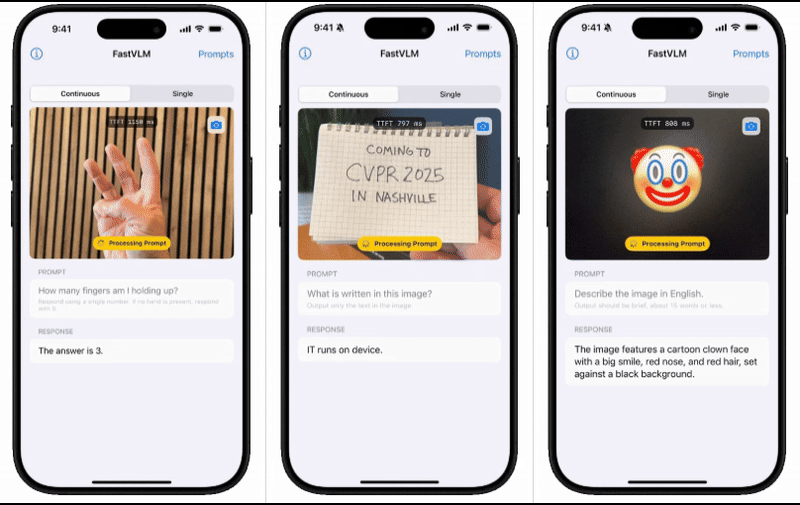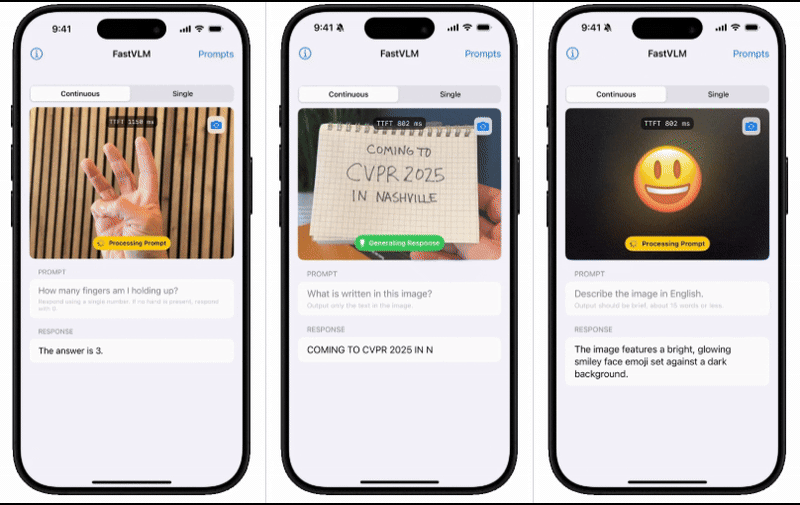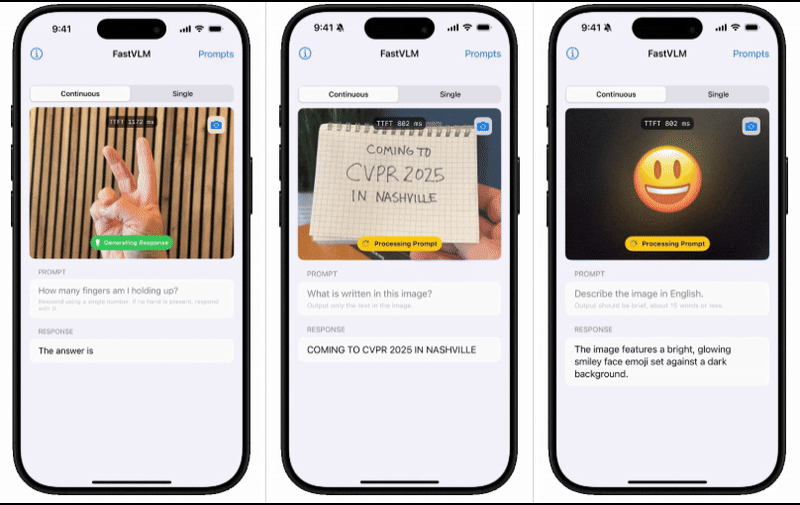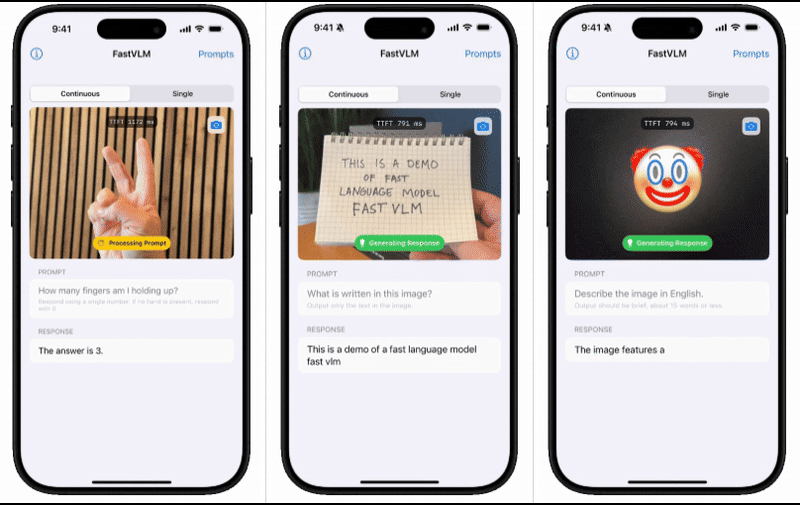
为了直观展示FastVLM的性能表现,苹果技术团队还推出了一款配套的iOS演示应用。这款应用通过实机演示,让用户能够亲身体验到移动端模型的出色表现。这一举措无疑进一步增强了用户对FastVLM的信心和期待。
苹果技术团队在介绍中表示,基于对图像分辨率、视觉延迟、词元数量与LLM大小的综合效率分析,他们成功开发出了FastVLM。这款模型在延迟、模型大小和准确性之间实现了最优权衡,为用户提供了更为高效、便捷的体验。
展望未来,FastVLM的应用场景将十分广泛。特别是针对苹果正在研发的智能眼镜类穿戴设备,FastVLM的本地化处理能力将有效支持这类设备脱离云端实现实时视觉交互。这一技术的突破,无疑为苹果在智能穿戴设备领域的布局注入了新的活力。
MLX框架的推出进一步增强了苹果的端侧AI技术生态。这一框架允许开发者在Apple设备本地训练和运行模型,同时兼容主流AI开发语言。这为开发者提供了更为灵活、高效的开发环境,进一步推动了苹果端侧AI技术的发展。