大型语言模型在深度扩展过程中面临的信息衰减问题,一直是制约其性能提升的关键瓶颈。华中科技大学电子信息与通信学院与字节跳动Seed团队联合攻关,提出深度混合注意力机制(MoDA),为突破这一技术瓶颈提供了创新方案。该研究成果发表于学术平台arXiv,论文编号为arXiv:2603.15619v1。
随着模型层数增加,早期处理的重要信息会逐渐被稀释,就像传话游戏中信息传递越远越容易失真。传统解决方案存在明显局限:残差连接虽能缓解梯度消失问题,但会将历史信息压缩成单一线索,导致关键特征丢失;密集连接虽能完整保留历史信息,但计算复杂度随层数平方增长,在大型模型中难以应用。研究团队通过重新设计信息传递方式,在保留历史信息与控制计算开销之间找到平衡点。
MoDA的核心创新在于将序列级注意力与深度级注意力融合到统一框架中。每个注意力头在处理当前层信息时,可自适应访问所有前置层的关键信息。具体实现上,模型为每个序列位置构建扩展键值序列,前半部分为标准序列信息,后半部分为深度历史信息,通过掩码机制确保因果性约束。在写入阶段,当前层的键值对会被追加到深度流中,供后续层调用。
研究团队通过硬件感知设计显著提升了计算效率。针对深度键值缓存的非连续访问问题,提出块感知布局方案,将查询分块处理,每个块仅访问对应局部深度区域。结合分组查询注意力特性,进一步开发组感知计算方法,使有效深度利用率提升至G/C(G为组大小,C为块大小)。实验数据显示,优化后的实现在64K序列长度下达到FlashAttention-2效率的97.3%。
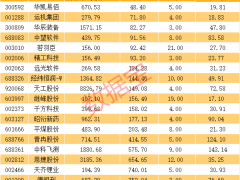
在模型性能验证方面,研究团队使用OLMo2数据集训练了700M和1.5B参数规模的模型。实验表明,MoDA在10个验证基准上平均降低0.2困惑度,在10个下游任务中平均提升2.11%性能,而计算开销仅增加3.7%的FLOPs。消融研究显示,深度键值投影组件贡献显著,单独使用即可降低0.41训练困惑度,添加前馈网络投影后性能进一步提升。
注意力可视化分析揭示了MoDA的独特工作机制。模型在中间层和后期层会主动分配注意力权重给深度历史信息,不同类型注意力头形成分工协作:尖锐头在保持序列关注的同时分配部分概率给深度位置,宽泛头则更多依赖深度信息。这种模式使注意力分布更广泛,突破了传统模型对固定汇聚位置的依赖。
针对不同深度配置的实验表明,MoDA在48层深层模型和24层浅层模型中均能稳定改善性能。特别在后归一化配置下,48层模型的验证损失改善幅度达到0.0409,是预归一化配置的10倍。渐进式优化实验显示,从朴素实现到完全优化版本,运行时间缩短了1458倍,验证了硬件感知设计的重要性。
尽管MoDA已实现高效硬件实现,但研究团队指出,在万亿参数规模的工业级部署中仍需突破内存瓶颈。为此提出有界深度键值槽缓存方案,通过固定大小的缓冲区动态管理深度信息,可采用动态选择或滑动窗口策略。这种设计将内存开销从深度依赖转为槽位依赖,为超大规模模型训练提供了可行路径。
该研究开源了完整实现代码,为学术界和产业界提供了可直接应用的技术方案。MoDA通过创新的信息组织方式,而非简单增加参数规模,为构建更深层、更强大的AI系统开辟了新方向。其硬件友好的设计理念,也展现了理论研究与工程实践相结合的价值。