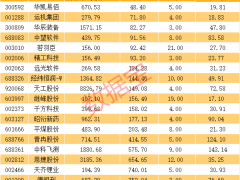
在人工智能算力竞争愈发激烈的当下,英伟达凭借GPU在市场中占据主导地位,然而如今其地位正受到挑战。近期,苹果披露其Apple Intelligence全部由TPU训练;Anthropic签下数十亿美元订单采购TPU训练Claude;meta也与谷歌签署数十亿美元协议租用TPU运行Llama。这一系列动态表明,谷歌的TPU正逐渐在市场中崭露头角。
TPU作为谷歌的“秘密武器”,在过去十年驱动着谷歌几乎所有核心产品。直到TPU训练的Gemini 3取得出色成果,人们才开始重新审视这款从搜索推荐系统中诞生的定制芯片。前谷歌TPU工程师Henry深度参与了三代TPU的研发,见证了大模型时代TPU的关键转型。他从硬件架构、软件生态、生产供应链博弈三个维度,揭开了TPU的神秘面纱。
TPU与GPU在设计哲学上截然不同。Henry用“流水线”与“大厨们”来比喻两者架构差异:GPU起源于图形处理,采用SIMT架构,如同厨房里众多独立思考的大厨并行处理多种任务;而TPU是专为机器学习矩阵计算定制的加速器,通过芯片间互联构建3D Torus网络,让数千张芯片协同工作,如同一张芯片,减少了调度和调控,提高了计算单元使用率。
在大规模部署场景中,TPU展现出独特优势。Henry表示,在软硬件深度协同下,TPU能对整颗TPU Pod进行全局算子融合与内存管理优化,将硬件性能“榨干”到极致,实现比GPU更低的推理成本。例如,谷歌的Ironwood芯片在物理参数上接近英伟达的GB200,在训练Gemini模型时,若谷歌为其他大模型公司定制,性价比(TCO)可能更高。因为TPU可根据已知任务负载进行物理芯片和软件层面的定制,保证每个计算单元都有任务,提高利用率。
然而,TPU也存在明显短板。在软件生态方面,尽管TPU已向外部客户开放,但其编译工具XLA仍是一个“黑盒”,外部团队难以独立完成调优。开发者使用TPU时,上层可选用PyTorch、JAX和TensorFlow等语言,XLA将其转化为TPU指令,但外部开发者很难独立处理或修补bug,需依赖谷歌工程师或其专门对接外部客户的软件组。
产能方面,TPU面临诸多挑战。HBM(高带宽内存)生产被SK hynix、三星和Micron三家公司垄断,英伟达是HBM最大客户,TPU作为次要客户,此前难以获得优质订单。同时,CoWoS是台积电的核心产能,TPU的HBM内存芯片和计算芯片需通过2.5D stacking封装成集成芯片,此过程谷歌和博通都无法完成,只能依赖台积电。良率也是问题,TPU主打芯片间通信,失败率高于GPU,且作为定制芯片,良率不佳则芯片报废,而GPU可降级使用。
在定制芯片领域,TPU需提前预测模型走向。以MoE(混合专家模型)为例,此前在TPU和GPU上运行效果不佳,直到TPU V4推出3D torus架构和OCS(光交换机),通过软件更改通信路径,解决了MoE的痛点。但芯片设计流程漫长,从设计到量产最快需两年到两年半、三年,而模型每6个月就变化一次,TPU需在两年前预测模型方向。虽然目前V7押对了方向,但未来若模型范式变化,TPU的先发优势可能被蚕食。
供应链方面,博通在TPU生产中扮演关键角色。博通负责TPU的通信ICI设计,将芯片物理连接并布局拓扑网络。谷歌与博通的合作可争取到更好的CoWoS和HBM产能,但博通议价权逐渐增大,对谷歌成本控制不利。同时,HBM产能被英伟达垄断,未来几年HBM可能决定芯片训练效率上限。
回顾TPU的发展历程,其最初是针对内部CNN大模型的加速器,第一代仅为推理芯片。Jeff Dean和图灵奖获得者David Patterson深度参与了第一代架构设计。第二代成为旗舰训练模型,用于AlphaGo、PaLM等训练。此后,针对推荐和排序算法加入Sparse Core,V5、V6进入大模型时代,针对Transformer进行优化并推出推理版本。
英伟达收购的Groq公司也值得关注。Groq踩准了推理、ASIC和Agent元年三个时间点,其芯片主做推理,针对低延迟场景,是编译器的公司而非芯片公司。创始人Jonathan Ross曾是TPU编译器团队成员,将TPU编译器经验带到Groq。Groq的LPU通过编译器精准确定每个计算单元任务,确定性高,适合Agent、实时语音和高频交易等对延迟要求高的场景。
随着人工智能发展,推理芯片市场将分层并分应用场景。谷歌和TPU将占据大规模部署的高层市场,中间和下层市场将有更多参与者。未来,TPU和GPU将并存,形成定制与通用、垂类场景相结合的健康生态,为用户带来成本降低后的无限可能。