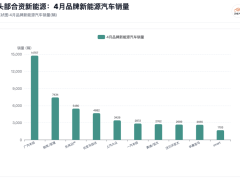
在AI视频生成领域,创作者长期面临一个核心痛点:模型难以精准理解人类意图。当用户试图将晴天场景改为雪天,或要求将动画嵌入商场LED屏时,现有工具常出现雪花堆砌、透视错乱等问题。字节商业化技术团队近日推出的开源框架Bernini,通过"先理解后生成"的创新机制,为行业提供了突破性解决方案。
该框架采用双模型协作架构,由多模态大模型(MLLM-based planner)与扩散模型(DiT-based renderer)构成。前者负责语义解析与规划,通过分析文本指令、源视频及参考素材,生成包含内容结构、编辑区域等关键信息的"语义草图";后者则基于规划结果进行视觉渲染,确保生成画面在光照、透视、运动关系等方面保持时空连续性。这种分工机制使视频编辑从"指令响应"升级为"意图理解"。
在天气变换测试中,系统能同步调整天空云层、路面反光、建筑阴影等20余个环境参数,使雪天场景呈现真实的积雪厚度变化与光线衰减效果。更突破性的是镜头语言控制能力,创作者可通过指令调整画面焦点,实现从前景咖啡杯到背景窗外街景的平滑过渡,或保持主体身份不变的前提下修改动作轨迹——当棕熊视频被要求改为"跳舞"时,系统能精准控制四肢运动幅度,同时维持环境光照与镜头稳定性。
针对AIGC创作中常见的"描述偏差"问题,Bernini引入多模态参考机制。在材质替换测试中,输入布料纹理参考图后,系统能自动识别盘子表面属性,生成具有织物褶皱与纤维质感的视觉效果,且该特征会随物体运动保持稳定。风格迁移功能支持跨维度适配,当用户输入赛博朋克风格参考图时,系统不仅调整色彩基调,还能为原始视频中的汽车添加霓虹灯带、为建筑添加全息投影等细节元素。
该框架的另一创新在于多素材协同处理技术。当需要将油画植入街头招牌时,系统通过SA-3D RoPE空间编码机制,自动识别参考图与源视频的时空坐标关系,生成符合透视原理的嵌入效果,有效解决传统方法常见的边界闪烁问题。在多元素组合测试中,系统成功将大理石雕塑、猫耳耳机、热带短裤等无关参考图,融合为站立在落日海滩的虚拟角色,各部件比例与光照关系保持高度协调。
技术文档显示,Bernini在Arena基准测试中已达到行业顶尖水平,特别是在复杂场景编辑任务中展现出显著优势。目前开源的Bernini-R版本聚焦视觉渲染模块,完整版预计将整合更强大的语义规划能力。开发者可通过GitHub、Hugging Face等平台获取代码,项目主页提供了详细的操作指南与案例演示。