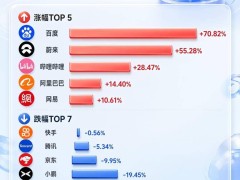
百度近日宣布推出新一代基础模型文心5.1,在参数压缩和成本优化方面取得显著突破。该模型总参数量缩减至前代的三分之一左右,激活参数量压缩近半,预训练算力成本仅为同规模业界模型的6%。这一技术革新通过弹性训练方法实现,从已训练的子模型矩阵中直接选用最优结构,避免了重复训练的高昂成本。
在性能表现上,文心5.1展现出差异化竞争力。根据LMArena最新榜单,该模型在全球文本生成大模型中排名第14位,与OpenAI、xAI等头部企业的模型存在微小差距。具体测试显示,其在工具调用数学推理能力上仅次于Gemini-3.1 Pro,多轮工具协作交互能力与Claude-Opus-4.6相当,但在深度搜索Agent任务中仍落后于国际顶尖模型。知识推理测试中,该模型在高阶学科推理和复杂指令遵循方面表现突出,但在纯数学推理和通用知识问答领域存在明显短板。
技术架构层面,文心5.1实现了三大创新:分离式架构设计将训练、推理等核心环节独立部署,通过高性能网络实现数据流与控制流分离;统一FP8低精度算子库的应用使训练推理稳定性提升50%;异构弹性调度系统将闲置CPU资源用于逻辑计算密集型任务,显著缩短训练迭代周期。后训练流程采用"专家训练-能力融合"四步法,通过在线策略蒸馏技术将代码、推理等确定性能力与创意写作等高熵能力有机结合,既保证训练效率又避免能力冲突。
实际场景测试中,文心5.1展现出独特优势与局限。在数学推理测试中,该模型能准确运用指示变量法和分布法解决概率问题,步骤完整且结果正确。信息整合任务中,面对模糊需求可自主拆解任务逻辑,通过表格对比和场景匹配提供实用建议。电子表格操作测试显示,其能完成基础数据分析需求,但需要多次指令调整才能实现理想效果。编程能力测试暴露明显短板,生成的游戏代码存在界面遮挡和操作失效问题,复杂项目代码无法正常运行。
该模型提供快速模型和思考模型两种版本,后者在创意写作和数据分析场景中表现更优。测试显示,思考模型生成的悬疑故事大纲结构完整,伏笔呼应自然;科幻小说叙事流畅但存在人物设定混乱问题。在门店运营数据分析任务中,思考模型能准确计算业绩均值和中位数,生成规范的数据表格,整体表现优于快速模型。这些特性使其在内容创作、知识问答、基础办公等场景具有实用价值,但在高阶专业领域仍需持续优化。