在科技领域,尤其是人工智能板块,多家知名企业正引领着全球多模态大模型行业的蓬勃发展。这些企业包括阿里巴巴(在香港和纽约两地上市)、百度(同样在香港和美国上市)、腾讯(港股与OTC市场交易)、科大讯飞(深交所上市)、万兴科技(深交所上市)、三六零(上交所上市)、昆仑万维(深交所上市)、云从科技(上交所科创板上市)以及拓尔思(深交所上市)等。
追溯全球大模型产业的发展轨迹,我们可以清晰地看到其阶段性成长。从1956年至2005年,人工智能作为一门学科诞生,神经网络模型逐步兴起,这一时期被视为早期探索期。随后,自2006年至2019年,深度学习概念被重新发掘并广泛应用,Transformer等模型的出现推动了整个行业的快速发展,这一时期被定义为快速成长期。2020年至2022年,大模型迎来了兴起期,模型的参数规模急剧膨胀,2022年更是被誉为大模型的元年。自2023年起,大模型开始进入广泛应用期,其在各个领域的应用不断深化,这一过程体现了技术发展的连续性和阶段性特征。
在全球人工智能服务器市场方面,由于大模型对计算能力和数据有着极高的需求,因此所需的服务器设施在人工智能基础设施市场中的占比将持续上升。据IDC预测,全球人工智能硬件市场(特指服务器)的规模将从2022年的195亿美元增长至2026年的347亿美元,五年复合增长率高达17.3%。其中,用于运行生成式人工智能的服务器市场规模在整体人工智能服务器市场中的占比将从2023年的11.9%增长到2026年的31.7%。
算力需求方面,随着人工智能从感知智能向生成式智能的转变,其对“强算法、高算力、大数据”的依赖程度日益加深。模型的大小、训练所需的参数量等因素将直接影响智能涌现的质量。以ChatGPT模型为例,其背后的GPT-3大模型所需训练参数量高达1750亿,算力消耗为3640PF-days(即每秒运算一千万亿次,持续运行3640天),至少需要1万片GPU提供支持。据统计分析,当模型参数扩大十倍时,算力投入将超过十倍,具体增加的倍数还会受到模型架构、优化效率、并行处理能力以及算力硬件能力等因素的影响。
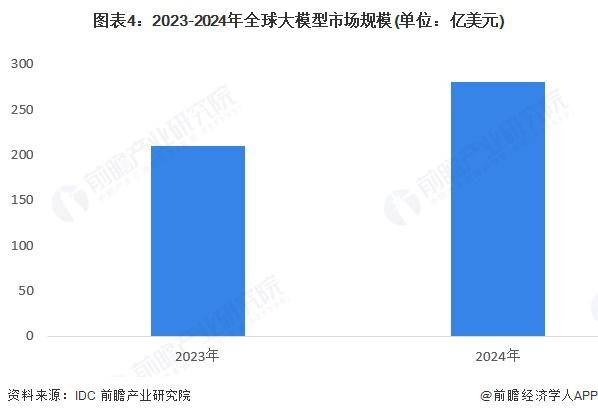
市场规模方面,当前全球人工智能产业正处于高速发展期,大模型技术引领着人工智能领域迈向新的高度。大模型市场不仅局限于技术讨论的范畴,更已进入商业化应用阶段,市场规模快速增长。根据IDC数据,2023年全球大模型市场规模已达到210亿美元。初步估算,2024年这一数字将增长至280亿美元,同比增长33%。
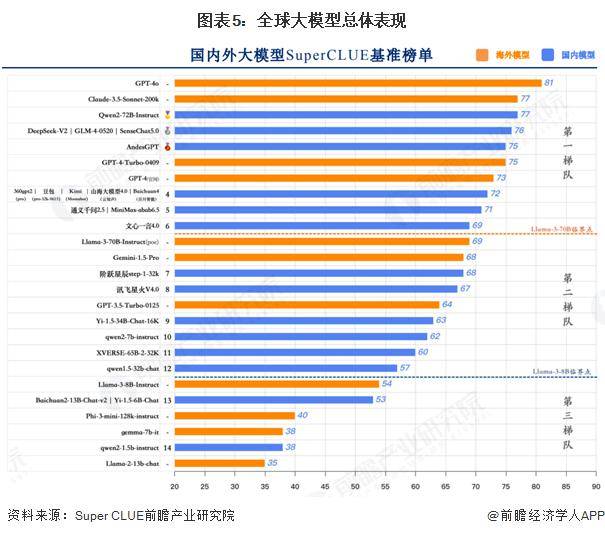
在全球多模态大模型的竞争格局中,2024年上半年,SuperCLUE发布了《中文大模型基准测评报告》。该报告选取了国内外具有代表性的33个大模型(6月份版本),通过多维度综合性测评,对国内外大模型的发展现状进行了深入观察与思考。在代表通用能力的一级总分方面,GPT-4o以81分的绝对优势领跑SuperCLUE基准测试,成为全球唯一超过80分的大模型,展现出强大的语言、数理和指令遵循能力。中国大模型的发展同样迅猛,其中有6个国内大模型的表现超过了GPT-4-Turbo-0409,绝大部分闭源模型的表现也已超越GPT-3.5-Turbo-0125。