近期,科技领域迎来了一项关于多模态人工智能(AI)的重要进展。据报道,苹果公司的工程师与法国索邦大学的研究人员携手,针对多模态AI的模型融合策略进行了深入探索。
多模态AI的核心在于同时处理图像、文本等多种数据类型,然而,如何有效整合这些异构数据一直是业内的一大挑战。当前的主流方法多采用后期融合策略,即分别使用预训练的单模态模型,如视觉编码器和语言模型,再将它们的结果进行组合。尽管这种方法操作简便,但其局限性也显而易见:由于单模态预训练带来的固有偏差,模型难以捕捉跨模态之间的依赖关系,从而限制了真正的多模态理解。
随着系统规模的扩大,不同组件的参数、预训练需求和扩展特性差异显著,这不仅增加了计算资源分配的复杂性,还影响了整体性能,特别是在需要深度多模态推理的任务中表现尤为明显。
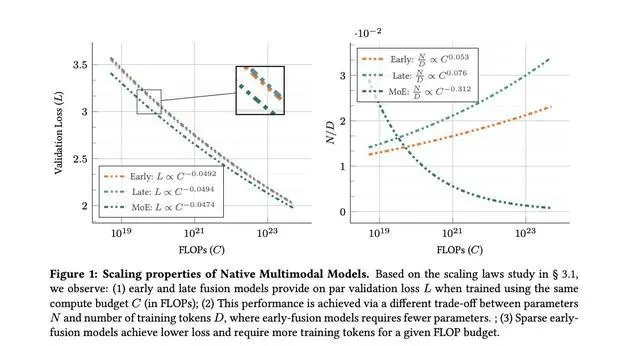
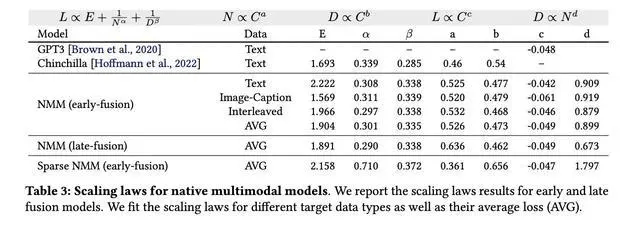
针对这些问题,苹果与索邦大学的联合团队提出了一种新的思路,他们深入研究了从头训练的原生多模态模型(NMMs)的扩展特性,并对比了早期融合与后期融合模型的效果。研究结果显示,在从头训练的情况下,早期融合模型与后期融合模型在性能上相当,但早期融合模型在低计算预算下展现出了更高的效率和更好的扩展性。
进一步的研究还探索了专家混合(MoE)稀疏架构的潜力。这种架构能够动态分配参数,针对不同模态进行专项优化。与稠密模型相比,稀疏模型在性能上有了显著提升,特别是在小规模模型中,优势更为明显。分析显示,稀疏模型更倾向于优先扩展训练数据而非活跃参数,这与稠密模型的扩展模式形成了鲜明对比。
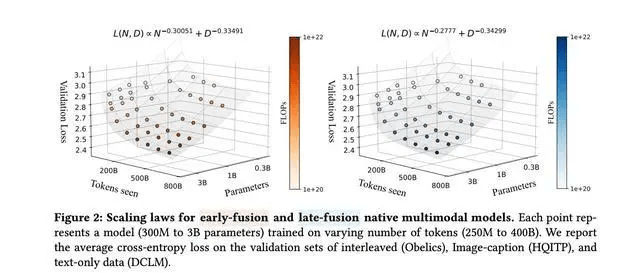
为了验证这些发现,研究团队进行了系统实验,训练了从0.3亿到40亿活跃参数的多模态模型。实验结果表明,原生多模态模型的扩展规律与语言模型相似,但跨模态数据类型和训练组合会对扩展系数产生一定影响。在等效推理成本下,稀疏模型持续优于密集模型,展现出在处理异构数据方面的强大能力。
这一研究成果不仅挑战了传统的多模态AI设计理念,还为未来高效多模态AI系统的发展指明了方向。统一早期融合架构与动态参数分配的结合,有望成为推动多模态AI领域进步的重要动力。