在当今产业智能化浪潮中,企业正积极探索如何利用自身专有知识资产,构建专属的认知引擎,以推动智能决策与高效运营。然而,传统检索增强生成(RAG)技术受限于语言单模态处理,只能实现文本知识库与文本查询间的浅层次理解,难以满足复杂业务场景的需求。两大主要缺陷逐渐显现:一是信息表征缺失,未能充分利用多模态富文档中的视觉语义信息,如版面结构、图表关系及公式特征;二是模态交互受限,无法支持图文混合查询和跨模态关联检索等多样化需求。
为解决这些痛点,一款名为Taichu-mRAG的多模态检索增强生成框架应运而生。该框架基于统一多模态细粒度检索引擎和紫东太初多模态大模型,旨在提升内容理解与生成质量,实现对多模态信息的协同感知、精准检索与深度推理问答。Taichu-mRAG在多模态富文档理解和多模态细粒度实体属性问答两大权威基准上取得了显著突破。
具体而言,在M3DocVQA数据集上,Taichu-mRAG的端到端问答准确率相比开源的SOTA M3DocRAG提升了33%,多模态检索召回率提高了12%;在E-VQA数据集上,其端到端问答准确率相较于开源的SOTA EchoSight提升了9%,多模态检索召回率同样提升了9%。
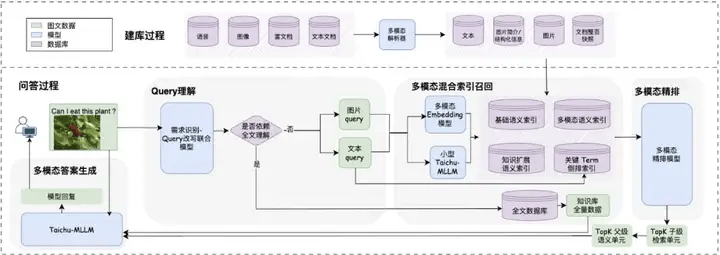
Taichu-mRAG整体架构面向新一代智能问答场景,包含四大核心模块:Query理解模块、多模态混合索引召回模块、多模态精排模块以及多模态增强答案生成模块。

Query理解模块能够深度挖掘用户需求,根据用户Query及对话上下文判断是否需要触发全文理解,并结合对话历史对Query进行智能扩展和改写,确保检索到最相关的知识。多模态混合索引与召回模块则通过特征抽取、索引建库及多路召回,对富文档进行多维度理解,抽取出子级检索单元块,并通过多模态Embedding模型抽取语义特征,在统一语义空间内进行ANN索引建库。当收到改写的Query后,该模块采用多路召回,高效召回TopN知识片段。
多模态精排模块则对召回的TopN知识片段进行精细化排序,采用单塔结构,深度融合Query、文本、图像、布局特征等信息,确保排序结果精准稳定。多模态答案生成模块则根据前序模块给出的相关参考知识和用户原始Query,联合生成最终答案,并给出答案的参考片段,便于用户进行答案溯源。当候选片段无法覆盖答案时,多模态大模型会根据用户自定义配置选择拒答或依赖自身知识进行开放式回答。
Taichu-mRAG的多模态检索引擎采用了双层级父子关联索引机制和多路异构特征联合检索技术。双层级父子关联索引机制通过父级语义单元和子级检索单元的智能分块和关联策略,有效解决了多模态数据检索中的粒度适配与上下文整合难题。子级检索单元精准召回语义最相关的细粒度语义片段,而父级语义单元则为关联的子级检索单元提供完整的上下文信息,提升大模型的回答精度和完整度。
多路异构特征联合检索则通过多模态Embedding模型实现多种模态在统一空间的语义表征,支持文本、图像、图表、公式等多种混合形式,形成互补增强的检索矩阵,确保检索系统的精准性和产业落地可行性。